class: center, middle # Replicate and the Apply Family of Functions - 3 ## Introductory Computer Programming ### Deepayan Sarkar <h1 onclick="document.documentElement.requestFullscreen();" style="cursor: pointer;"> <svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" fill="currentColor" class="bi bi-arrows-fullscreen" viewBox="0 0 16 16"> <path fill-rule="evenodd" d="M5.828 10.172a.5.5 0 0 0-.707 0l-4.096 4.096V11.5a.5.5 0 0 0-1 0v3.975a.5.5 0 0 0 .5.5H4.5a.5.5 0 0 0 0-1H1.732l4.096-4.096a.5.5 0 0 0 0-.707zm4.344 0a.5.5 0 0 1 .707 0l4.096 4.096V11.5a.5.5 0 1 1 1 0v3.975a.5.5 0 0 1-.5.5H11.5a.5.5 0 0 1 0-1h2.768l-4.096-4.096a.5.5 0 0 1 0-.707zm0-4.344a.5.5 0 0 0 .707 0l4.096-4.096V4.5a.5.5 0 1 0 1 0V.525a.5.5 0 0 0-.5-.5H11.5a.5.5 0 0 0 0 1h2.768l-4.096 4.096a.5.5 0 0 0 0 .707zm-4.344 0a.5.5 0 0 1-.707 0L1.025 1.732V4.5a.5.5 0 0 1-1 0V.525a.5.5 0 0 1 .5-.5H4.5a.5.5 0 0 1 0 1H1.732l4.096 4.096a.5.5 0 0 1 0 .707z"/> </svg> </h1> --- <!-- # Topics * Replicating a simulation experiment * The `*apply()` family of functions * Functions can be arguments of other functions --> # Recap * `lapply(X, FUN)` applies the function `FUN` on each element of `X` * Extra arguments to `FUN` can also be supplied (but these remain fixed for each call) * These extra arguments can be named to control which argument of `FUN` varies --- layout: true # The `lapply()` function --- * Example: $N(0, \sigma^2)$ variates with varying $\sigma$ ```r str(rnorm) ``` ``` function (n, mean = 0, sd = 1) ``` ```r str(lapply(1:5, FUN = rnorm, n = 1, mean = 0)) ``` ``` List of 5 $ : num 1.31 $ : num -0.404 $ : num 4.8 $ : num 2.27 $ : num 4.66 ``` -- * But much easier to do directly using vectorization ```r rnorm(5, mean = 0, sd = 1:5) ``` ``` [1] -0.6534446 0.8223748 0.2362248 -0.7187763 -4.7389152 ``` --- * A more complicated example: IQR of 1000 $N(0, \sigma^2)$ variates with varying $\sigma$ ```r str(lapply(1:8, function(s) IQR(rnorm(n = 1000, mean = 0, sd = s)))) ``` ``` List of 8 $ : num 1.29 $ : num 2.8 $ : num 4.23 $ : num 5.31 $ : num 7.14 $ : num 8.54 $ : num 9.64 $ : num 11.2 ``` --- layout: true # `sapply()` : simplifying results to vector / array --- * `sapply()` is essentially the same as `lapply()`, but simplifies result if possible ```r sapply(1:8, function(s) IQR(rnorm(n = 1000, mean = 0, sd = s))) ``` ``` [1] 1.438662 2.521442 3.844622 5.687218 6.340752 8.379334 9.189600 11.092355 ``` ```r sapply(1:6, function(s) quantile(rnorm(n = 1000, mean = 0, sd = s))) ``` ``` [,1] [,2] [,3] [,4] [,5] [,6] 0% -3.01909455 -6.71109675 -10.22607397 -12.6133527 -17.20452654 -19.7840226 25% -0.58429112 -1.42523774 -2.21403417 -2.4976569 -3.22198064 -3.6256299 50% 0.01664107 -0.04724582 -0.01402486 0.2755438 0.02214483 0.3556058 75% 0.64007241 1.31447731 1.88614944 2.9299217 3.71264289 3.8678318 100% 2.97056464 6.31140128 9.66990832 11.4005221 15.53770158 23.6443821 ``` --- layout: true # `apply()` : Apply function to rows / columns of a matrix --- * We will talk about matrix operations in R in more detail later * It is often useful to apply a function on rows or columns of a matrix ```r m1 <- matrix(0, nrow = 1000, ncol = 8) for (i in 1:8) m1[, i] <- rnorm(1000, mean = 0, sd = i) str(m1) ``` ``` num [1:1000, 1:8] 0.986 -1.111 1.993 0.687 1.329 ... ``` * Note that this is essentially the same as ```r m2 <- sapply(1:8, function(s) rnorm(n = 1000, mean = 0, sd = s)) str(m2) ``` ``` num [1:1000, 1:8] -2.3043 -1.1596 -0.3159 0.0255 1.3727 ... ``` --- * Suppose we want to compute the mean for each column of `m1` * There are several ways to do this: - Loop over columns - Write this as a matrix operation (will discuss later) - Use the `colMeans()` or `colSums()` function ```r colMeans(m1) ``` ``` [1] -0.04943950 -0.09688866 0.09234992 -0.25304376 -0.07945579 -0.09594082 0.08744955 -0.06326630 ``` ```r colSums(m1) / nrow(m1) ``` ``` [1] -0.04943950 -0.09688866 0.09234992 -0.25304376 -0.07945579 -0.09594082 0.08744955 -0.06326630 ``` --- * However, `colMeans()` / `colSums()` and `rowMeans()` / `rowSums()` are special * Other summary functions do not have a built-in row-wise / column-wise versions * `apply()` allows arbitrary functions to be called per row (`MARGIN=1`) or column (`MARGIN=2`) ```r apply(m1, 2, mean) ``` ``` [1] -0.04943950 -0.09688866 0.09234992 -0.25304376 -0.07945579 -0.09594082 0.08744955 -0.06326630 ``` ```r apply(m1, 2, sd) ``` ``` [1] 1.007114 2.007653 3.076955 4.086972 5.091051 5.801682 7.099011 7.949074 ``` ```r apply(m1, 2, IQR) ``` ``` [1] 1.299213 2.765086 4.313662 5.467725 6.739437 7.418080 9.378087 11.111943 ``` --- * `apply()` also allows additional arguments to be specified ```r apply(m1, 2, quantile, probs = c(0.25, 0.75)) ``` ``` [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] 25% -0.7411409 -1.446932 -2.147665 -2.947431 -3.485082 -3.934525 -4.468243 -5.839906 75% 0.5580719 1.318154 2.165997 2.520294 3.254355 3.483555 4.909845 5.272037 ``` * As well as unnamed functions ```r apply(m1, 2, function(x) median(abs(x))) ``` ``` [1] 0.663239 1.374926 2.161410 2.753740 3.393707 3.650180 4.676070 5.503559 ``` --- * Applying a function row-wise ```r apply(m1, 1, function(x) which.max(abs(x))) ``` ``` [1] 4 6 8 2 8 8 8 4 3 8 8 5 5 6 8 7 7 7 6 8 5 8 6 7 4 5 5 8 7 8 8 8 8 6 8 3 8 6 8 4 8 5 8 5 5 7 4 [48] 7 8 8 7 7 8 7 8 6 7 7 7 5 7 5 6 7 8 8 8 8 8 4 8 4 4 8 7 6 7 7 8 5 8 5 4 6 7 7 8 8 8 4 8 7 5 4 [95] 8 6 7 8 8 8 6 8 4 8 5 7 7 4 6 4 5 5 8 5 7 4 5 8 4 7 5 5 6 5 7 6 8 5 8 8 5 7 7 8 7 4 7 7 2 8 7 [142] 5 5 7 8 8 5 6 7 6 8 8 8 7 6 8 8 7 7 8 5 8 8 7 7 5 7 8 7 5 8 7 7 7 6 5 6 8 5 7 8 8 7 8 5 7 8 6 [189] 7 7 8 5 5 6 5 8 8 8 4 7 6 8 7 7 8 4 7 5 7 6 4 5 8 4 8 8 8 7 5 6 5 8 5 7 4 8 8 6 8 7 8 8 8 4 8 [236] 7 7 8 5 7 8 5 4 8 5 8 6 7 8 7 8 6 7 7 7 5 7 7 8 7 6 6 8 5 7 4 7 8 6 8 7 8 7 6 4 8 7 6 3 8 4 5 [283] 4 3 4 8 6 6 8 7 4 7 7 5 8 7 8 4 6 8 6 7 8 8 5 8 8 8 7 7 7 8 8 6 8 8 5 8 4 8 6 8 8 6 8 8 7 7 8 [330] 5 5 6 5 4 7 6 7 7 6 4 6 5 7 8 6 7 8 7 7 8 5 7 5 5 8 8 8 8 8 8 8 7 3 4 7 6 8 5 5 7 6 4 8 5 6 6 [377] 8 8 5 7 6 8 8 8 4 4 7 3 6 7 8 8 8 7 4 6 8 8 7 7 6 6 5 6 5 7 6 3 5 6 6 4 8 6 8 8 6 8 4 8 8 7 7 [424] 7 8 7 7 8 8 7 6 6 8 8 7 4 7 3 3 6 5 7 7 7 6 4 5 8 5 6 7 8 7 6 4 6 5 4 7 8 7 8 7 4 5 7 7 8 5 7 [471] 7 3 6 5 5 7 8 8 8 5 8 6 8 8 5 8 8 8 5 6 6 8 5 6 7 7 8 5 4 7 6 7 5 8 6 8 5 6 5 5 3 8 8 5 8 5 2 [518] 8 6 7 7 6 5 7 5 5 8 6 6 8 5 8 8 6 8 3 8 8 7 7 5 8 5 7 7 4 8 8 8 7 8 5 5 5 4 6 4 8 8 8 8 7 7 6 [565] 7 5 6 5 8 6 5 7 8 7 4 8 7 8 5 7 7 7 8 7 7 7 7 8 7 7 3 8 3 4 8 7 8 7 7 7 8 6 7 8 3 6 3 8 6 8 8 [612] 6 7 8 8 8 7 6 6 5 6 8 5 7 8 6 8 7 7 7 6 8 7 4 6 8 5 6 8 5 3 5 3 7 6 4 8 6 3 6 3 8 8 8 8 8 8 6 [659] 8 7 8 6 7 4 5 8 7 7 6 4 6 7 8 7 7 7 7 7 6 6 7 4 6 8 5 4 8 6 6 4 8 7 7 7 8 5 7 8 7 8 7 8 6 5 6 [706] 7 6 7 8 6 7 8 4 6 6 8 8 5 6 7 5 6 7 6 6 4 6 6 6 7 7 4 7 7 6 8 8 7 7 8 8 7 7 6 7 6 8 6 6 8 5 8 [753] 7 5 7 8 7 8 6 8 8 6 7 6 8 7 8 5 8 8 4 6 6 4 7 6 8 8 8 8 8 6 8 8 7 4 5 6 7 7 6 6 8 6 5 7 8 8 7 [800] 7 5 7 5 6 8 6 8 6 7 7 7 7 7 8 5 8 3 7 6 8 7 6 7 5 8 5 8 8 5 4 8 8 7 7 8 7 5 8 8 5 5 6 8 5 8 5 [847] 8 7 5 8 6 7 8 4 6 8 8 7 8 6 6 8 6 8 6 5 8 8 7 5 6 7 6 7 6 5 8 6 3 7 3 8 7 6 5 7 8 4 7 8 7 8 3 [894] 7 6 8 8 8 7 3 8 6 6 6 8 8 8 2 7 8 6 8 7 7 8 7 8 6 6 7 5 8 8 7 8 8 8 7 4 8 7 8 5 7 3 5 7 6 7 7 [941] 7 5 8 5 6 7 8 7 6 8 8 7 8 6 7 6 8 7 5 8 3 5 4 8 8 8 3 6 3 4 7 8 7 8 7 8 6 3 7 4 8 4 5 8 6 8 5 [988] 5 5 3 7 5 8 7 8 8 8 8 8 8 ``` --- * Applying a function row-wise ```r wmax <- apply(m1, 1, function(x) which.max(abs(x))) table(wmax) ``` ``` wmax 2 3 4 5 6 7 8 4 31 73 139 168 255 330 ``` ```r barplot(table(wmax)) ``` 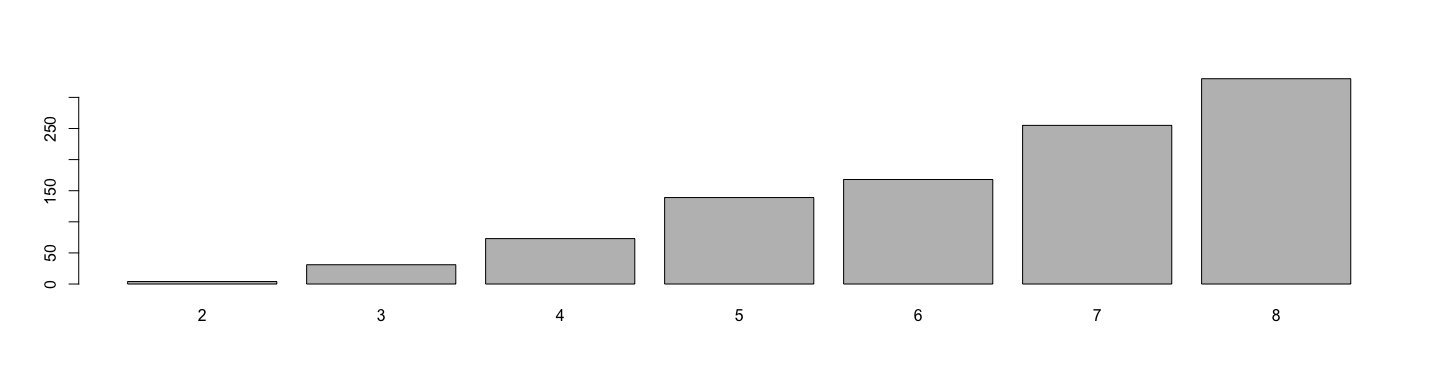 --- layout: true # `apply()` function to margins of an array --- * `apply()` can also summarize over margins of higher-dimensional arrays ```r Titanic.adult <- Titanic[, , "Adult", ] Titanic.adult ``` ``` , , Survived = No Sex Class Male Female 1st 118 4 2nd 154 13 3rd 387 89 Crew 670 3 , , Survived = Yes Sex Class Male Female 1st 57 140 2nd 14 80 3rd 75 76 Crew 192 20 ``` --- * `apply()` can also summarize over margins of higher-dimensional arrays ```r apply(Titanic.adult, MARGIN = 3, sum) ``` ``` No Yes 1438 654 ``` * More interestingly, the summary can happen over multiple dimensions ```r apply(Titanic.adult, MARGIN = c(2, 3), sum) ``` ``` Survived Sex No Yes Male 1329 338 Female 109 316 ``` --- * Another example: UC Berkeley admissions data .scrollable400[ ```r UCBAdmissions ``` ``` , , Dept = A Gender Admit Male Female Admitted 512 89 Rejected 313 19 , , Dept = B Gender Admit Male Female Admitted 353 17 Rejected 207 8 , , Dept = C Gender Admit Male Female Admitted 120 202 Rejected 205 391 , , Dept = D Gender Admit Male Female Admitted 138 131 Rejected 279 244 , , Dept = E Gender Admit Male Female Admitted 53 94 Rejected 138 299 , , Dept = F Gender Admit Male Female Admitted 22 24 Rejected 351 317 ``` ] --- * Sum over third dimension (department) to get total admissions by gender ```r apply(UCBAdmissions, c(1, 2), sum) ``` ``` Gender Admit Male Female Admitted 1198 557 Rejected 1493 1278 ``` ```r prop.table(apply(UCBAdmissions, c(1, 2), sum), margin = 2) ``` ``` Gender Admit Male Female Admitted 0.4451877 0.3035422 Rejected 0.5548123 0.6964578 ``` * The `prop.table()` function converts counts into proportions (in this case, by column) --- * We can write a small function to extract percent admitted ```r admittedPercent <- function(x) round(100 * prop.table(x, margin = 2)[1, ]) admittedPercent(apply(UCBAdmissions, c(1, 2), sum)) ``` ``` Male Female 45 30 ``` * This suggests that female candidates are rejected at a considerably higher rate -- * We can apply this to any specific department as well ```r admittedPercent(UCBAdmissions[,, 1]) ``` ``` Male Female 62 82 ``` * For the first department, the admission rates seem to be reversed --- * It is easier to use `apply()` again to do this for all departments ```r apply(UCBAdmissions, 3, admittedPercent) ``` ``` Dept Admit A B C D E F Male 62 63 37 33 28 6 Female 82 68 34 35 24 7 ``` * Contrary to aggregated results, this suggests that most departments have comparable rejection rates * Why this apparent contradiction? -- ```r apply(UCBAdmissions, c(2, 3), sum) # total candidates by department ``` ``` Dept Gender A B C D E F Male 825 560 325 417 191 373 Female 108 25 593 375 393 341 ``` --- layout: true # `tapply()` : Apply function over "ragged" array --- * Similar in spirit to `apply()`, but meant for groups of unequal size * General form: `tapply(X, INDEX, FUN, ..., simplify = TRUE)` * `X` is split according to grouping variable(s) `INDEX` * `FUN` applied to each subset --- * A simple example we have seen before ```r with(mtcars, tapply(mpg, am, FUN = mean)) ``` ``` 0 1 17.14737 24.39231 ``` --- * `FUN` can be have more complicated output ```r with(mtcars, tapply(mpg, am, FUN = summary)) ``` ``` $`0` Min. 1st Qu. Median Mean 3rd Qu. Max. 10.40 14.95 17.30 17.15 19.20 24.40 $`1` Min. 1st Qu. Median Mean 3rd Qu. Max. 15.00 21.00 22.80 24.39 30.40 33.90 ``` * The `simplify` argument controls form of return value * `simplify = FALSE` produces list output as usual * But `simplify = TRUE` (default) simplifies _only_ if `FUN` returns scalar values --- * Output of different size leads to list output as usual ```r with(mtcars, tapply(mpg, am, FUN = unique)) ``` ``` $`0` [1] 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4 14.7 21.5 15.5 13.3 $`1` [1] 21.0 22.8 32.4 30.4 33.9 27.3 26.0 15.8 19.7 15.0 21.4 ``` --- * Grouping by multiple variables is possible * With scalar-valued `FUN`, the default result is an array with groups as margins ```r with(mtcars, tapply(mpg, list(am, gear), FUN = mean)) ``` ``` 3 4 5 0 16.10667 21.050 NA 1 NA 26.275 21.38 ``` * Some combinations are empty in this case ```r with(mtcars, tapply(mpg, list(am, gear), FUN = length)) ``` ``` 3 4 5 0 15 4 NA 1 NA 8 5 ``` --- * `tapply()` essentially calls `split()` followed by `lapply()` * `split()` is often very useful to divide data into subsets for further manipulation .scrollable400[ ```r str(split(mtcars, mtcars$am)) ``` ``` List of 2 $ 0:'data.frame': 19 obs. of 11 variables: ..$ mpg : num [1:19] 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 ... ..$ cyl : num [1:19] 6 8 6 8 4 4 6 6 8 8 ... ..$ disp: num [1:19] 258 360 225 360 147 ... ..$ hp : num [1:19] 110 175 105 245 62 95 123 123 180 180 ... ..$ drat: num [1:19] 3.08 3.15 2.76 3.21 3.69 3.92 3.92 3.92 3.07 3.07 ... ..$ wt : num [1:19] 3.21 3.44 3.46 3.57 3.19 ... ..$ qsec: num [1:19] 19.4 17 20.2 15.8 20 ... ..$ vs : num [1:19] 1 0 1 0 1 1 1 1 0 0 ... ..$ am : num [1:19] 0 0 0 0 0 0 0 0 0 0 ... ..$ gear: num [1:19] 3 3 3 3 4 4 4 4 3 3 ... ..$ carb: num [1:19] 1 2 1 4 2 2 4 4 3 3 ... $ 1:'data.frame': 13 obs. of 11 variables: ..$ mpg : num [1:13] 21 21 22.8 32.4 30.4 33.9 27.3 26 30.4 15.8 ... ..$ cyl : num [1:13] 6 6 4 4 4 4 4 4 4 8 ... ..$ disp: num [1:13] 160 160 108 78.7 75.7 ... ..$ hp : num [1:13] 110 110 93 66 52 65 66 91 113 264 ... ..$ drat: num [1:13] 3.9 3.9 3.85 4.08 4.93 4.22 4.08 4.43 3.77 4.22 ... ..$ wt : num [1:13] 2.62 2.88 2.32 2.2 1.61 ... ..$ qsec: num [1:13] 16.5 17 18.6 19.5 18.5 ... ..$ vs : num [1:13] 0 0 1 1 1 1 1 0 1 0 ... ..$ am : num [1:13] 1 1 1 1 1 1 1 1 1 1 ... ..$ gear: num [1:13] 4 4 4 4 4 4 4 5 5 5 ... ..$ carb: num [1:13] 4 4 1 1 2 1 1 2 2 4 ... ``` ] --- layout: false # What else? ```r apropos("apply") # objects with 'apply' in their names ``` ``` [1] "apply" "dendrapply" "eapply" "kernapply" "lapply" "mapply" "rapply" [8] "sapply" "tapply" "vapply" ``` * Will not discuss in detail (see documentation): * `vapply()`: Safer version of `sapply()` with pre-specified return type * `mapply()`: Vectorized apply, where multiple arguments can be varied * `eapply()`: Apply over elements in an environment, which we can ignore for now * `rapply()`: Recursive apply (over complex lists), which we can also ignore for now * Others are even more specialized --- layout: false class: middle, center # Questions?